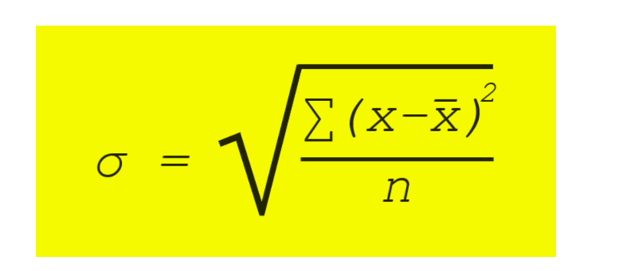Percentages van de normale verdeling
In deze blog vertellen we je wat de formules bij de normale verdeling zijn, hoe de percentages werken en waarom deze belangrijk zijn.
Auteur: Roos Spanjer
Laatst bijgewerkt op: 14 oktober 2025